
« Méfie-toi : les robots vont te crawler ! » Cela ferait presque peur. Que veut dire ce mot exactement ? Quelles pourraient en être les conséquences, positives ou négatives, pour mon site ?
Crawler est un mot anglais, cela veut dire collecter. C’est un robot appelé souvent spider >> qui est chargé de crawler tous les sites et documents qu’il peut trouver sur Internet, donc potentiellement sur votre site Web.
Il peut être programmé pour parcourir le Web, avec des objectifs déterminés. Il est sans cesse en action, et visite les pages en fonction d’un chemin préétabli.
L'un des plus connus est celui utilisé par Google, pour son moteur de recherche nommé Googlebot. Avant lui, c’était AltaVista qui utilisait Scooter.
Actuellement, il y a tellement de pages Internet que les robots d’indexation doivent limiter leur temps sur chaque site afin d'en visiter le plus possible. De fait, un crawler visite donc, en général, seulement une partie du site à chaque passage.
Vous avez intérêt à ce que votre site soit crawlé par les robots, et cela le plus souvent possible. Pour autant, il est encore plus important que leur crawl finisse par un classement en première page des SERP (Search Engine Response Page : les pages de réponse des moteurs de recherche). Pour cela, vous devez bien faire la distinction entre :
C’est forcément une décision de votre part. Pour une raison qui vous appartient, vous avez indiqué aux moteurs de recherche que vous ne vouliez pas que cette page soit visitée, ni indexée par les robots.
Pour les empêcher de crawler votre site, il faut indiquer la ou les URL des pages pour lesquelles vous souhaitez interdire l’accès. Pour cela, il vous faut publier ces directives dans le fichier robots.txt à la racine du site. Pour être très précis, sachez que :
Pour rappel, les pages orphelines sont :
Le passage des robots sur les pages peut être suivi par le web master en analysant les fichiers logs sur les serveurs, qui en indiquent l’historique de passage. Il existe aussi des outils payants en ligne :
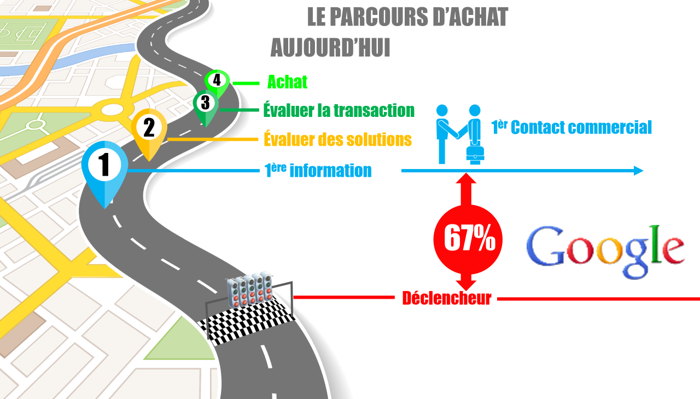
L’ inbound-marketing s’intéresse à captiver les prospects le long de leur parcours d’achat. Le parcours d’achat d’un prospect passe par plusieur [...]

Dans tout parcours d’achat, les prospects passent par 3 stades de maturité >> qui déterminent leurs choix de mots-clés dans leurs requêtes [...]